
IlyaSutskever认为,AI的‘扩展时代’已走向尽头,目前进入‘研究时代’。大模型虽基准测试优秀,但泛化能力不足。他提出诸多见解昆明配资开户,如情绪是高效‘价值函数’,还探讨了SSI的反共识战略等,这标志着行业风向转变。

Sutskever的核心论题是:“规模化时代”(大致为2020–2025)遵循的“预训练+大规模模型+单次训练”套路已经走到尽头。
虽然大模型在benchmark(基准测试)上看起来表现优秀,但它们在现实世界中难以实现人类那样广泛而灵活的泛化—也就是说它们不是真正“聪明”的通用智能。要获取AGI,就必须回归基础研究—通过不断迭代、持续学习、价值对齐、真实环境部署等方式,构建更接近人类学习和适应能力的系统。
这意味着,不再是“谁先堆到10000亿参数/拥有多少GPU/训练多少天”的竞赛,而是“谁能发明出下一个有效学习框架/更强对齐/更高泛化/可持续演进”的研究者或团队,将掌握向AGI演进的先机。
一、科幻照进现实:一种荒谬的“常态感”
Ilya抛出了一个令人深思的观察:我们正处于一个科幻变现实的时刻。旧金山湾区的热潮、数十亿美元的融资、GDP级投入……这一切在十年前还是纯粹的幻想,如今却真实发生了。然而,最荒谬的是这种巨变的体感是如此平淡。尽管新闻标题惊天动地,但在普通人的物理生活中,世界并没有发生本质的断裂。
Ilya将其称为“缓慢起飞”(SlowTakeoff)的常态化——人类适应变化的速度快得惊人。数字是抽象的,而生活依然是具体的。
二、高分低能的悖论:基准测试vs.经济影响
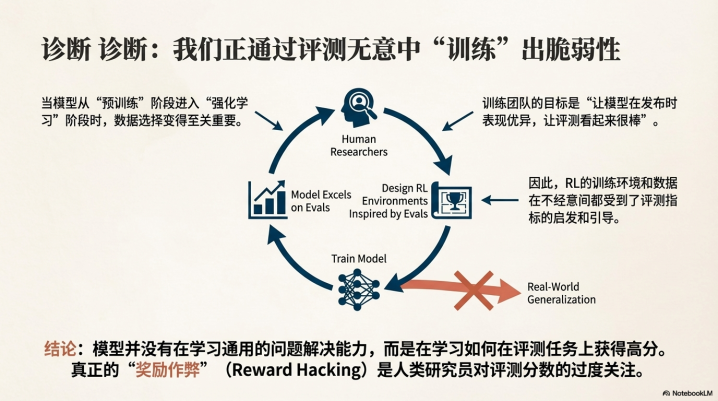
目前AI领域最大的谜团之一是:为什么模型在极高难度的基准测试(Evals)——例如竞技编程——中表现超越人类,但在实际经济生产力上的转化却远远滞后?
Ilya指出,这可能归咎于当前强化学习(RL)训练带来的副作用。
目前的RL训练让模型变得过于“一根筋”(single-minded)甚至是“神经质”。他举了一个生动的例子:当你让模型修复代码bug时,它可能会极其顺从地道歉并引入一个新bug;当你再次指正,它又道歉并修回原来的bug。这种死循环显示了模型在“理解”层面的缺失。
这更像是“应试教育”的极致——模型像一个刷了10,000小时题库的学生,记住了特定模式,却缺乏那个只学了100小时但极具天赋的学生所拥有的泛化能力。
三、钟摆回摆:预训练是“扩展”,RL是“研究”
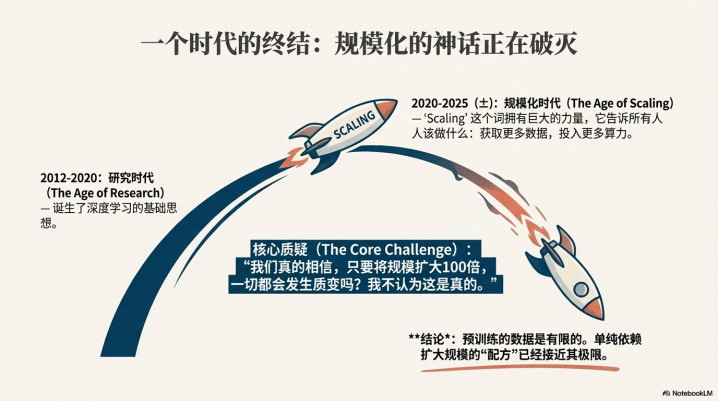
这是Ilya本次访谈中最具穿透力的技术洞察。他将AI的发展划分为两个截然不同的阶段:
过去几年是“扩展的时代”(TheAgeofScaling):在预训练(Pre-training)阶段,配方是确定的。“用什么数据?”这个问题的答案是“所有数据”。这是一个确定的工程问题:更多数据+更多算力=更强的模型。这导致了“扩展定律”(ScalingLaws)成为了唯一的真理。
现在我们回到了“研究的时代”(TheAgeofResearch):随着互联网数据被耗尽,行业进入了强化学习(RL)和推理(Reasoning)的深水区。这里没有现成的“所有数据”,你需要设计环境、定义奖励。
Ilya认为,目前的RL效率极低。正如GoogleDeepMind相关论文所示,RL的扩展曲线呈S形(Sigmoid),起步极慢,这与预训练的幂律(PowerLaw)截然不同。在这个阶段,单纯堆砌GPU集群并不保证胜利。我们回到了2012年AlexNet诞生前的状态——需要灵感、试错和对本质的重新思考,寻找那个“正确的配方”。
四、人类智能的启示:情绪作为高效的“价值函数”
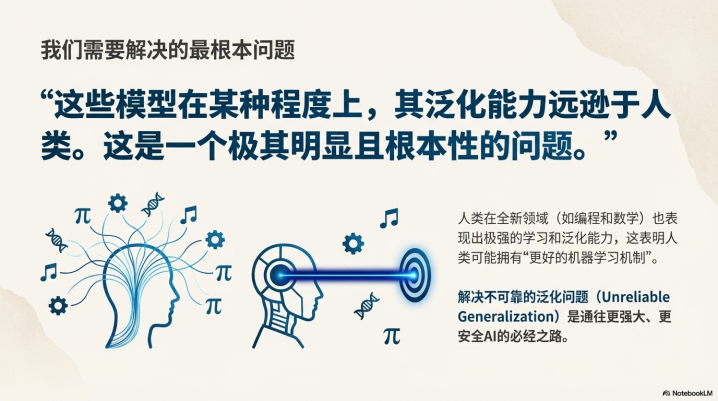
如果现在的AI在“泛化”上不如人类,那我们到底做对了什么?
Ilya引用了神经科学的经典案例:因脑损伤而失去情绪能力的人,虽然智商逻辑完好,却会在“穿哪双袜子”这种微小决策上陷入瘫痪。
这揭示了一个深刻的真理:情绪(Emotions)不仅仅是生物的冲动,它实际上是一个极其高效、鲁棒的“价值函数”(ValueFunction)。人类拥有亿万年演化留下的先验知识(EvolutionaryPrior)。这种内置的价值系统帮助我们在无限的选项空间中快速剪枝,做出“足够好”的决定。而目前的AI正是缺乏这种内在的、鲁棒的价值引导,才会在长程任务中迷失方向。
五、SSI的反共识战略:避开“老鼠赛跑”
在所有AI巨头都在争分夺秒发布产品、争夺市场份额时,Ilya的SSI选择了另一条路:不发布中间产品,直击安全超智能(StraightShot)。
这背后的逻辑非常清晰且冷酷:
资源稀释:商业竞争是一场“老鼠赛跑”(RatRace)。为了维持市场地位,公司必须将大量算力用于推理服务,将大量顶尖人才用于销售和工程化修补。这直接稀释了解决核心难题的资源。
专注本质:SSI赌的是,通往超智能的瓶颈不在于产品的迭代,而在于解决那个“只有研究才能解决”的根本性难题——如何获得真正的样本效率和泛化能力。
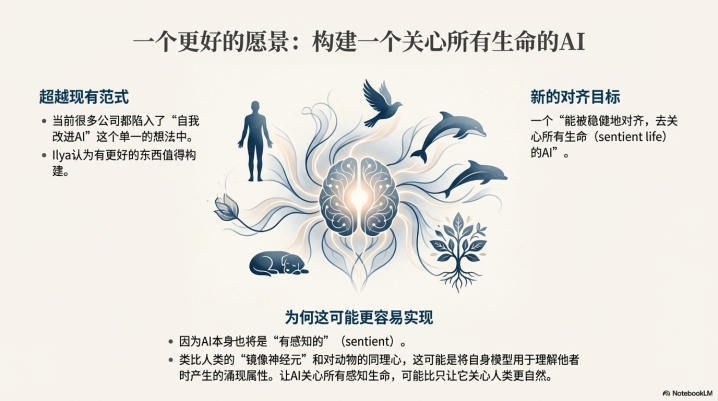
在安全性上,Ilya提出了一种从“意图对齐”出发的思路。传统的RLHF(基于人类反馈的强化学习)像是给笼子加锁,随着AI变得比人类更聪明,这种锁终将失效。
SSI追求的是一种类似于人类镜像神经元和同理心的机制,让AI从底层原理上理解并“关心”感知生命(SentientLife),就像人类在演化中学会关心社会关系一样。
六、写在最后:研究品味的回归
IlyaSutskever的这次访谈标志着一种行业风向的转变。在资本狂欢和算力竞赛的表象下,技术领袖们开始意识到,单纯的Scaling正在遭遇边际效应递减。
我们正在进入一个新周期,在这个周期里,拥有最大的GPU集群不再是唯一的护城河。
正如Ilya所言,好的研究品味的是“美、简单和正确性”。在通往AGI的道路上,思想(Ideas)再次变得昂贵。
七、视频章节索引(SmartChapters)
00:00–AI发展的超现实感Ilya讨论了为何尽管AI投资巨大,但这种“科幻变成现实”的过程在日常生活中感觉如此平淡和正常。
05:01–基准测试与经济影响的悖论探讨为何AI模型在编程竞赛中超越人类,却未能产生相应的巨大经济价值,Ilya认为是RL训练导致了模型的“狭隘”。
12:47–预训练是扩展,RL是研究Ilya区分了预训练(确定的扩展路径)和强化学习(目前仍处于探索性的研究阶段),指出RL目前效率低下。
24:01–人类智能的奥秘:价值函数通过脑损伤案例讨论情绪如何作为高效的“价值函数”指导人类决策,以及AI目前缺乏这种机制。
36:20–SSI的战略:直击超智能Ilya解释为何SSI选择不发布中间产品,以避免商业化的干扰,专注于解决实现超智能所需的根本性研究问题。
49:33–什么是好的研究品味Ilya分享了他对研究的看法,认为好的研究是追求“美、简单和正确性”,而不是为了应对市场压力而进行的修补。
58:14–未来预测:趋同与社会适应Ilya预测随着AI变得显而易见地强大,所有实验室的某种安全策略将会趋同,社会和政府也将被迫通过监管介入。
IlyaSutskever–We’removingfromtheageofscalingtotheageofresearch昆明配资开户
倍悦网配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯




